Building Custom LLMs with Ollama and Open WebUI
- Getting Started with Ollama
- Doing Prompt Engineering with Ollama Models
- Getting Started with Open WebUI
- Creating a RAG Model using Open WebUI
- Calling Models from Python Scripts
This post will walk you through getting started with Ollama, a command line application and library for downloading and using LLM models, and Open WebUI, a local, browser based interface for using Ollama models. Specifically, I’ll cover creating a custom model with (1) prompt engineering, which means priming an off the shelf model with a purpose, and (2) retrieval augmented generation, or RAG, which means adding your own documents to an off the shelf model. Ofcourse, you can and should combine these two techniques.
Getting Started with Ollama
Installing Ollama is incredibly easy, they’ve done a great job packaging their application. You just go to https://ollama.com and click their download button. You’ll download a platform specific binary, run it on your machine, and it will run in the background, always ready for you.
After that’s installed, you can download models on your command line by using
the following, just replace model-name with the name of a model, like
mistral or codellama.
ollama pull model-nameOnce you have a model, then you can run it in your console and have a
conversation with it. Again, replace model-name with the name of a model.
ollama run model-name You can list your models with,
ollama lsDoing Prompt Engineering with Ollama Models
Prompmt engineering is a fancy term for “writing a prompt” to prime your model
to interact with you in a certain way. Different models have different
parameters you can set. Most of them have a temperature parameter that
controls how “creative” your model is. The higher the temperature, the more
creative the model.
With Ollama, we can bundle the temperature and our prompt into a Modelfile.
From the Ollama docs we have this example.
FROM llama3.2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
"""Then we can create the model using the llama3.2 model, with a temperature of
1, and our prompt above.
ollama create mario -f ./Modelfile
ollama run mario
>>> hi
Hello! It's your friend Mario.Getting Started with Open WebUI
If you have Ollama installed, then you can install Open WebUI fairly easily. I
installed Open WebUI using Python and PIP, but I needed to use Python 3.11,
since that is what Open WebUI supports. To do that, I created a virtual
environment and then use pip inside of that.
python3.11 -m venv venv
source venv/bin/activate
pip install open-webuiFrom there, just run the following in your console, and then go to localhost:8080 in a browser.
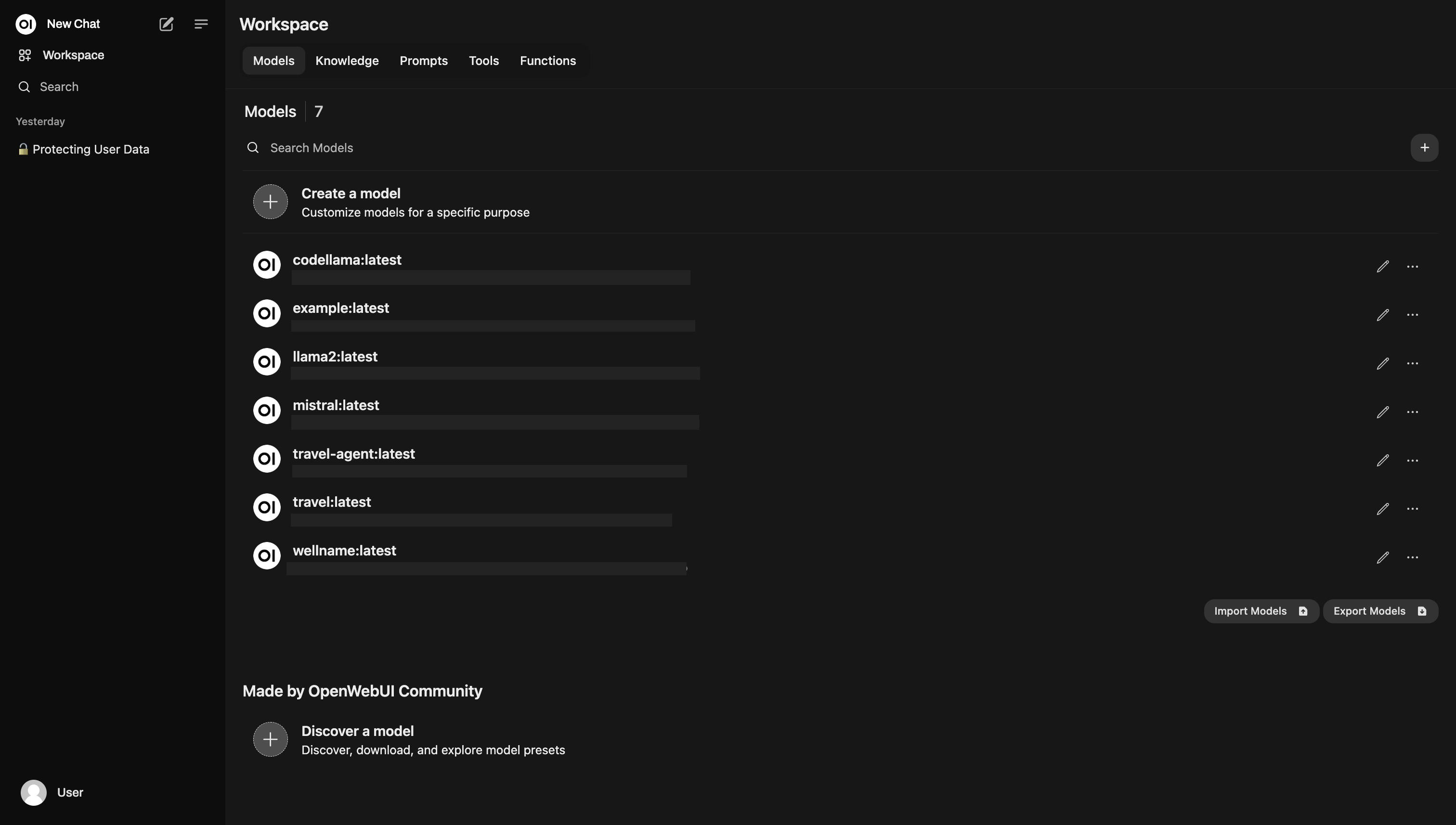
open-webui serveThen you should see all of your models from Ollama listed in your workspace.
Creating a RAG Model using Open WebUI
This basic idea is to create a “knowledge base” in Open WebUI, and then create a new custom model in Open WebUI, and add your knowledge base to your new model. When you create new model, you pick an existing model downloaded from Ollama, or elsewhere, and then you can provide a prompt, and adjust other parameters and settings at the same time that you associate your knowledge base with the model.
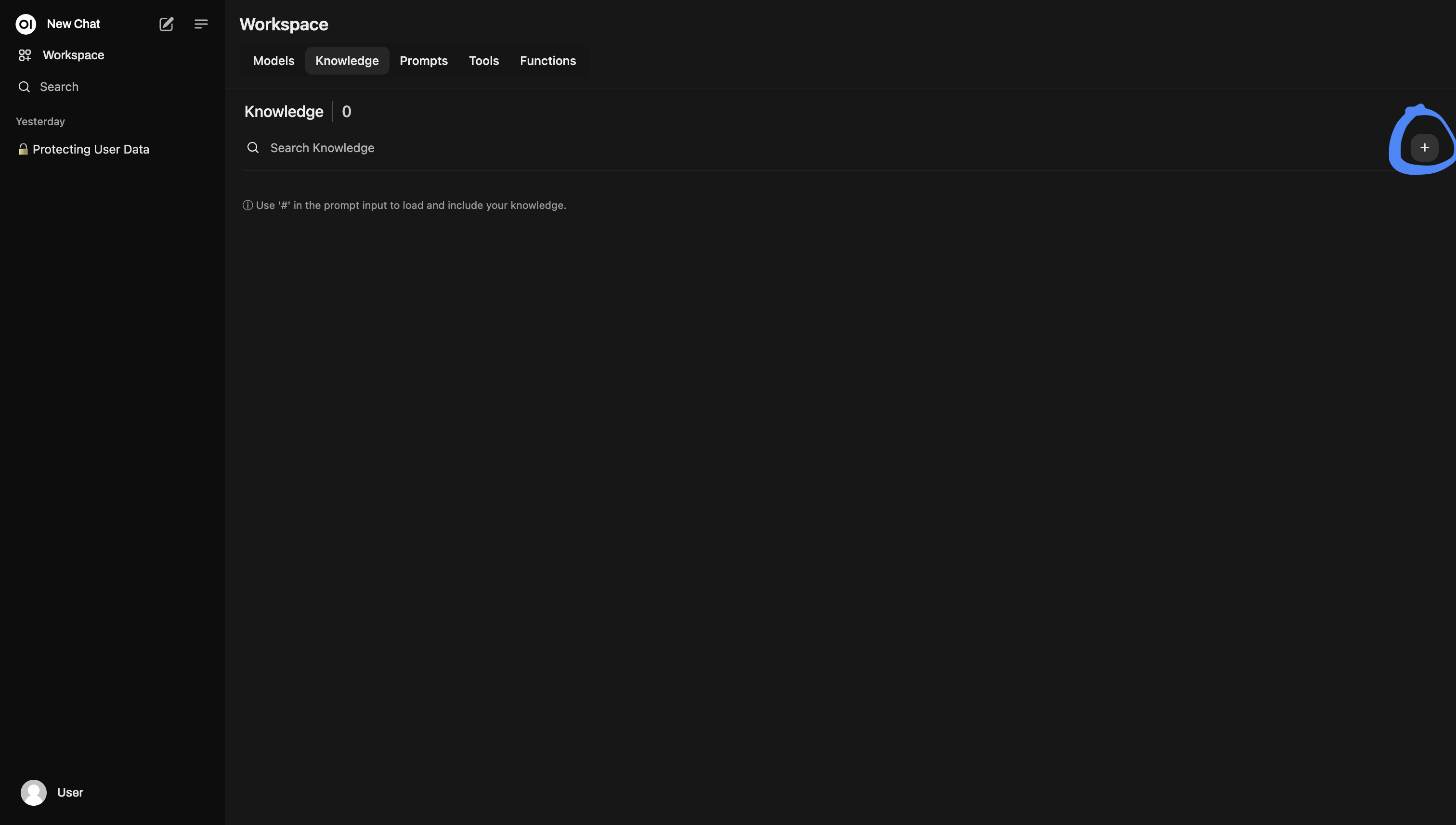
Alright, this is current as of October 18, 2024. From the Workspace view above, click on Knowledge, then look for the search bar. On the far right-hand side of the search bar, there is a button with a plus. Click that to create a knowledge base.
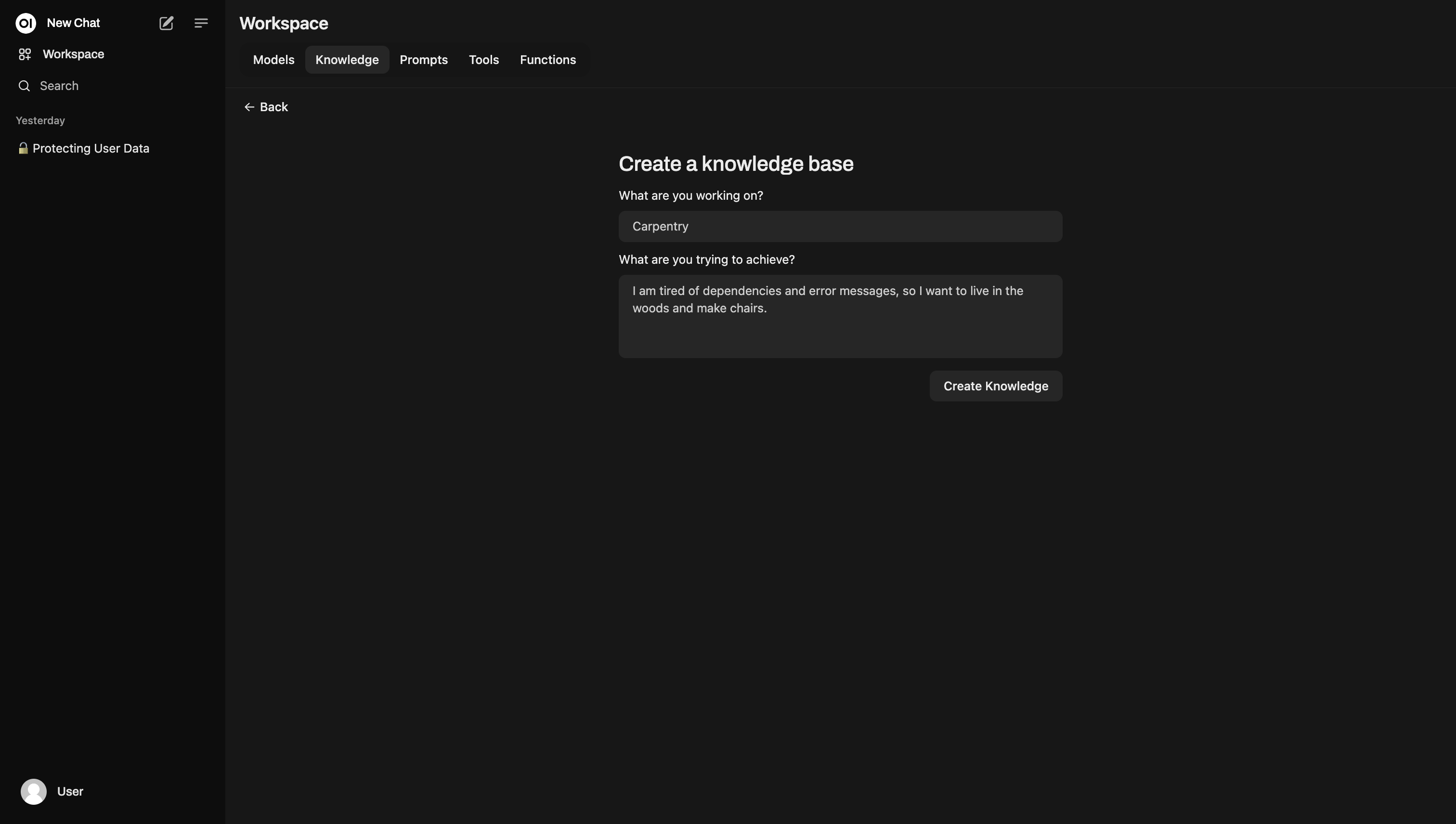
Then you will get a pop-up modal to describe your knowledge base…
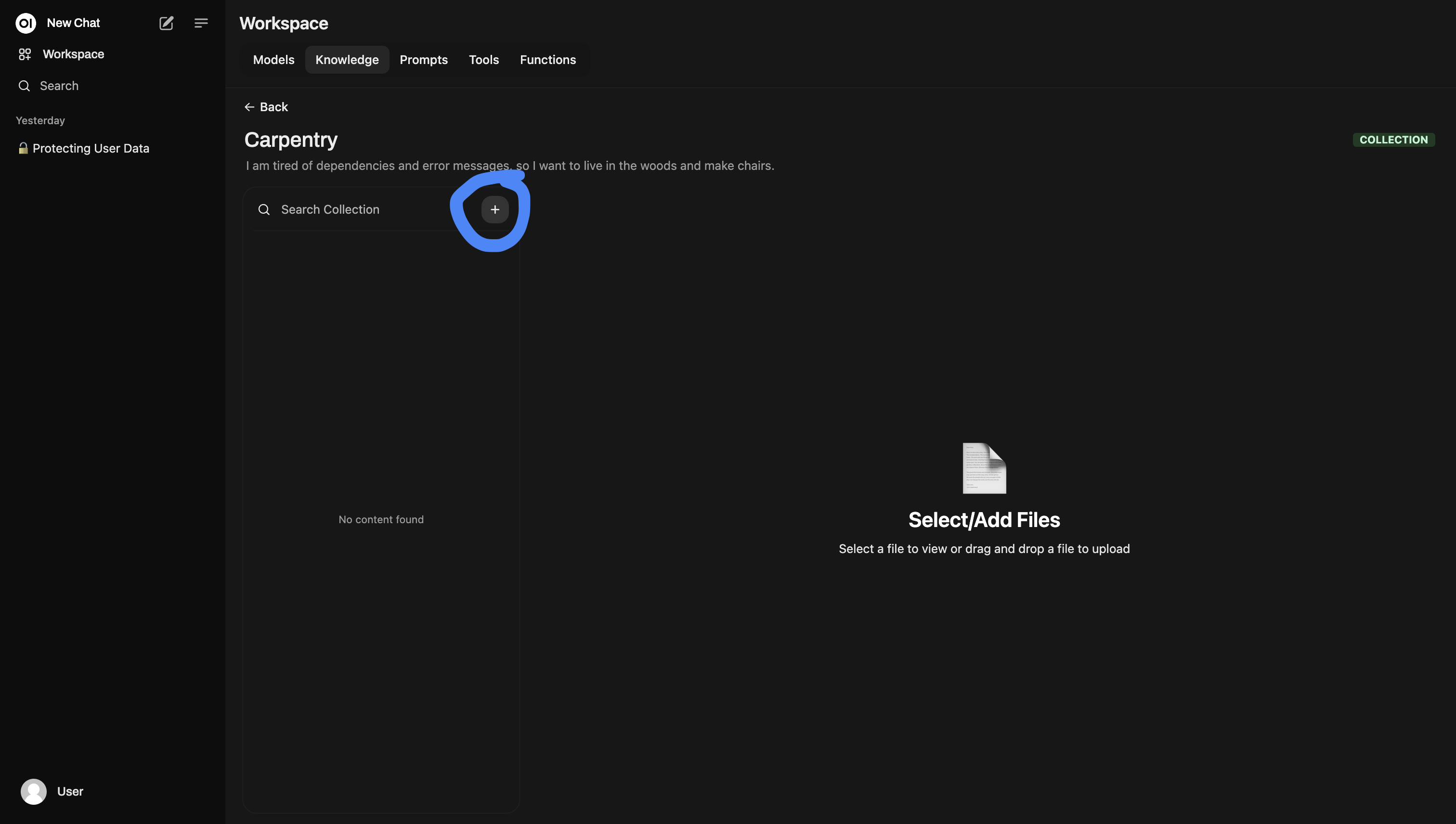
Then you can add documents with the plus button.
Calling Models from Python Scripts
Once you have created a new model in Open WebUI, and turned it into a RAG model by associating it with your own knowledge base, then you can reference that model from a Python script using Ollama.
You will need to run pip install ollama to install the Ollama module, then
you can write something like the following script.
import ollama
model_file='''
FROM llama2
SYSTEM You are a helpful squirrel that is very knowledgeable about fine woodworking.
'''
mode_lname = 'woodland-friend'
ollama.create(model=model_name, modelfile=modelfile)
def query_squirrel(content:str):
messages = [{
'role': 'user',
'content': content,
}]
resp = ollama.chat(model=model_name, messages=messages)
if not resp.get('done'):
raise TimeoutError('Squirrel timeout')
message = resp.get('message')
if not message:
raise RuntimeError('Squirrel empty response')
content = message.get('content')
if not content:
raise RuntimeError('Squirrel empty message')
return content
while True:
query = input('Query Helpful Squirrel: ')
if str(query) == "exit":
break
print(query_squirrel(query))